StepFunctsionsからGlue Crawlerを実行するステートには、「完了まで待つ」のような同期する仕組みが用意されていません。
そのため、StepFunctsions内でGlue Crawlerのエラーハンドリングするには、Crawlerを実行後に定期的に実行が完了したか確認し、完了したら結果を判定するという一連のフローを実装する必要があります。
この記事では、StepFunctsions内でGlue Crawlerのエラーハンドリングする一連のフローを作成する方法を解説します。
StepFunctsionsでGlue Crawlerのエラーハンドリングを実装
ステートマシンを作成
Glue Crawlerをエラーハンドリンしたフローは以下のようになります。
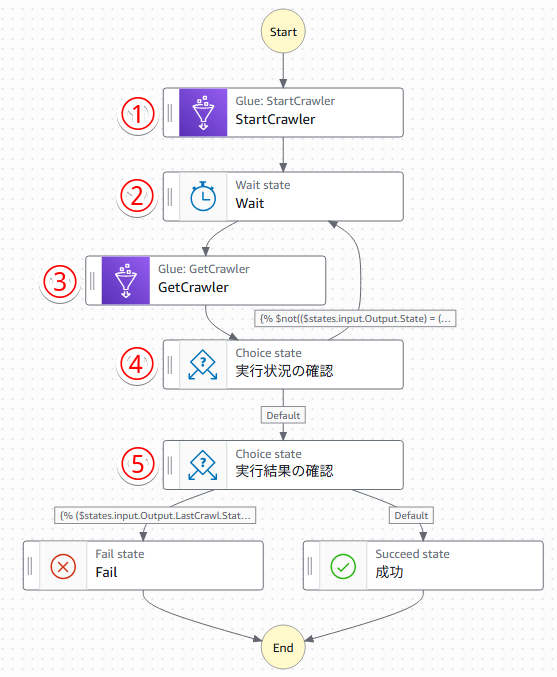
①StartCrawler:Grawlerを実行する
②wait:一定時間待機
③GetCrawler:Grawlerの情報を取得
④実行状況の確認(choice):Crawlerの実行が完了しているか確認
⑤実行結果の確認(choice):Crawlerの実行結果を確認
それぞれのステートの設定値は以下以下のように設定しています。
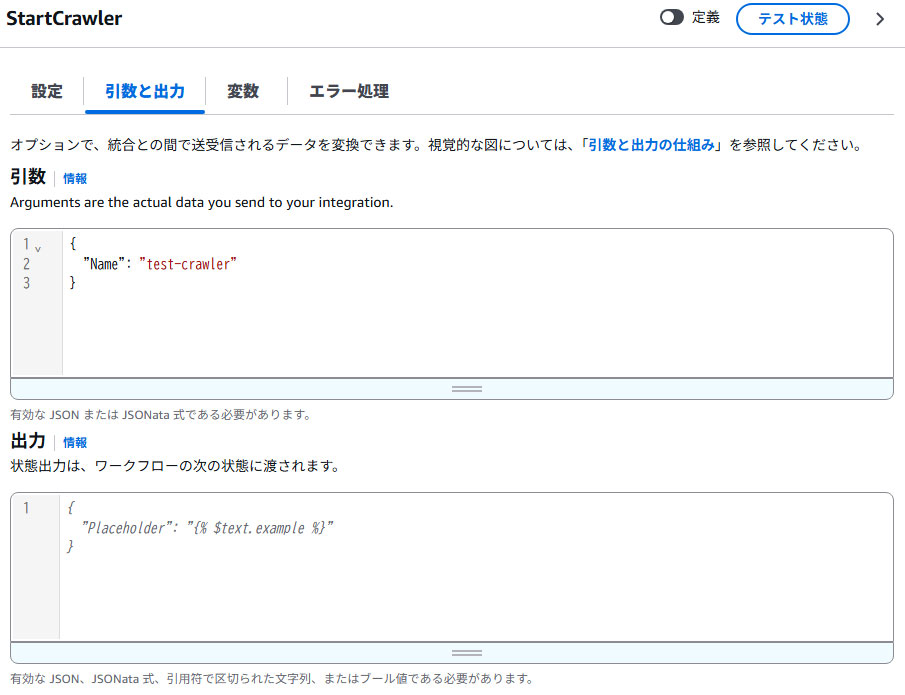
①StartCrawler
実行するCrawlerの名称を設定します。
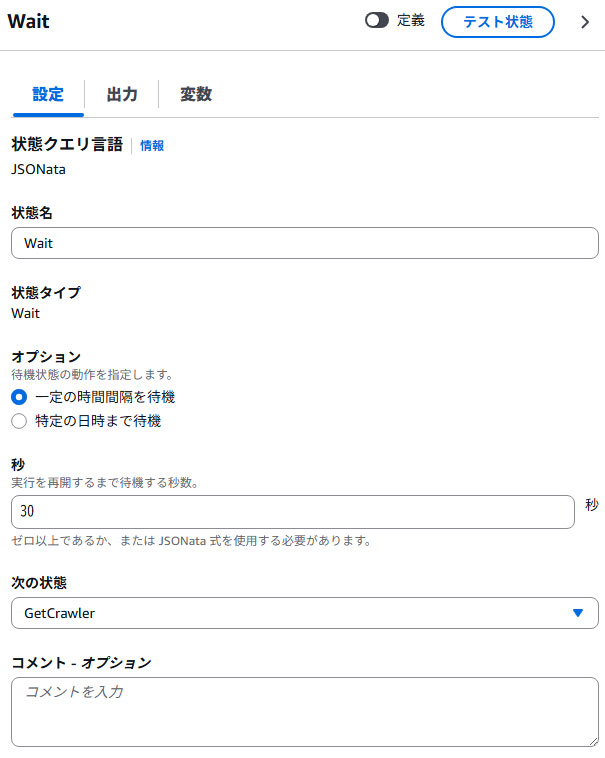
②wait
Crawlerの状態を取得しに行くまで待機する秒数を設定します。
長い秒数を設定すると、待機時間も長くなり、ステートマシン自体の処理時間が遅くなる原因にもなるため、短い秒数を設定したほうがよさそうです。
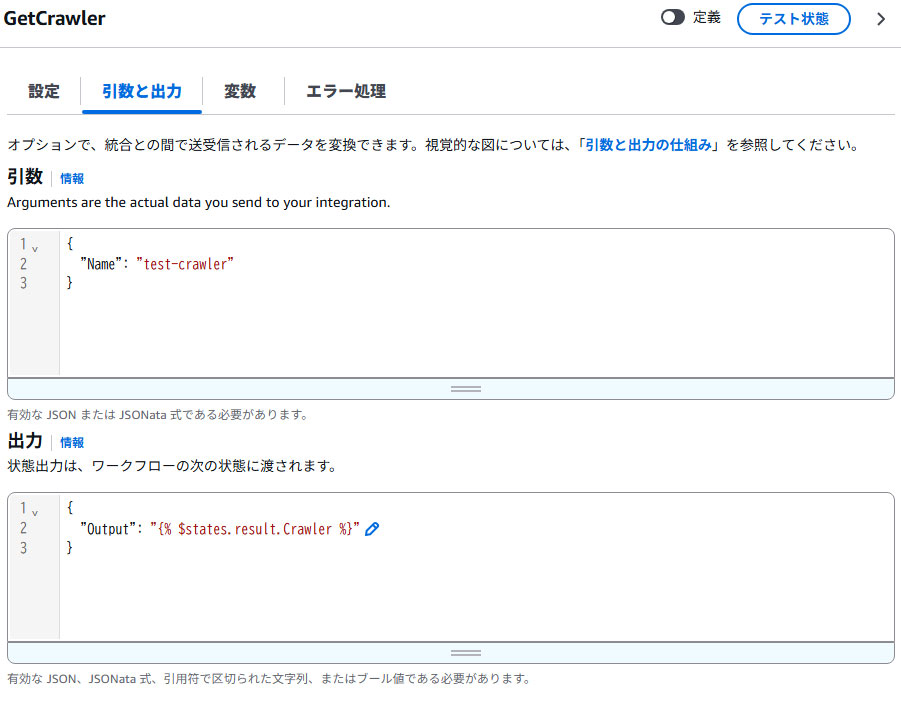
③GetCrawler
Crawlerの情報を取得するために、[引数]には「①StartCrawler」に設定したCrawlerと同じ名称を設定します。
[出力]ではOutputというキーでGetCrawlerのレスポンス情報を取得するように設定します。
ちなみに、GetCrawlerでは、以下のようなレスポンスが返却されます。
{
"Crawler": {
"Classifiers": [],
"CrawlElapsedTime": 0,
"CreationTime": "2025-12-19T01:33:40Z",
"DatabaseName": "test-db",
"LakeFormationConfiguration": {
"AccountId": "",
"UseLakeFormationCredentials": false
},
"LastCrawl": {
"LogGroup": "/aws-glue/crawlers",
"LogStream": "test-crawler",
"MessagePrefix": "77e6e213-9e3b-4485-a9b2-950d9f332284",
"StartTime": "2026-01-02T02:58:31Z",
"Status": "SUCCEEDED"
},
"LastUpdated": "2025-12-19T01:33:40Z",
"LineageConfiguration": {
"CrawlerLineageSettings": "DISABLE"
},
"Name": "test-crawler",
"RecrawlPolicy": {
"RecrawlBehavior": "CRAWL_EVERYTHING"
},
"Role": "service-role/xxxxxxxxx",
"SchemaChangePolicy": {
"DeleteBehavior": "DEPRECATE_IN_DATABASE",
"UpdateBehavior": "UPDATE_IN_DATABASE"
},
"State": "READY",
"TablePrefix": "test-",
"Targets": {
"CatalogTargets": [],
"DeltaTargets": [],
"DynamoDBTargets": [],
"HudiTargets": [],
"IcebergTargets": [],
"JdbcTargets": [],
"MongoDBTargets": [],
"S3Targets": [
{
"Exclusions": [],
"Path": "s3://bucket/trn/"
}
]
},
"Version": 1
}
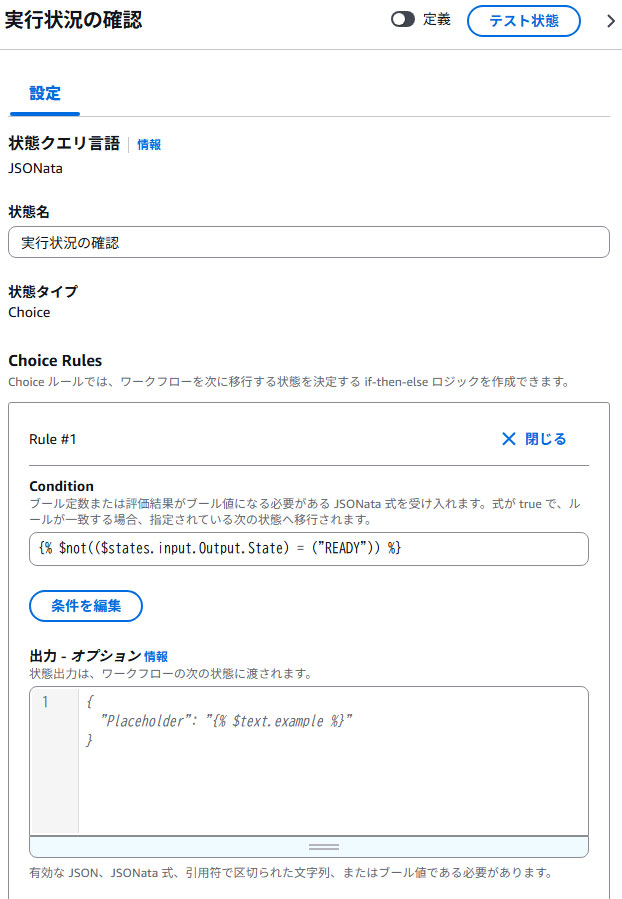
}④実行状況の確認(choice state)
GetCrawlerのレスポンス情報のStateを判定します。
Stateには下記の3つの状態がありますが、ここではREADYだったらCrawlerの実行が完了しているとみなしています。それ以外の場合は②waitへ遷移して再度一定時間待機します。
- READY:実行待ち
- RUNNING:実行中
- STOPPING:停止中
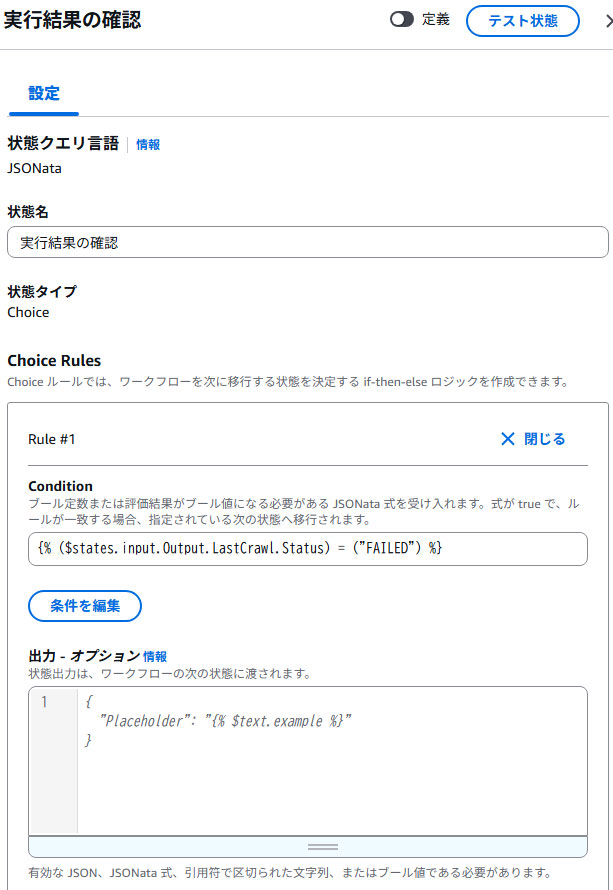
⑤実行結果の確認(choice state)
GetCrawlerのレスポンス情報のLastCrawl.Statusを判定します。
このStatusがFAILEDの場合はCrawlerの実行は失敗したことになります。
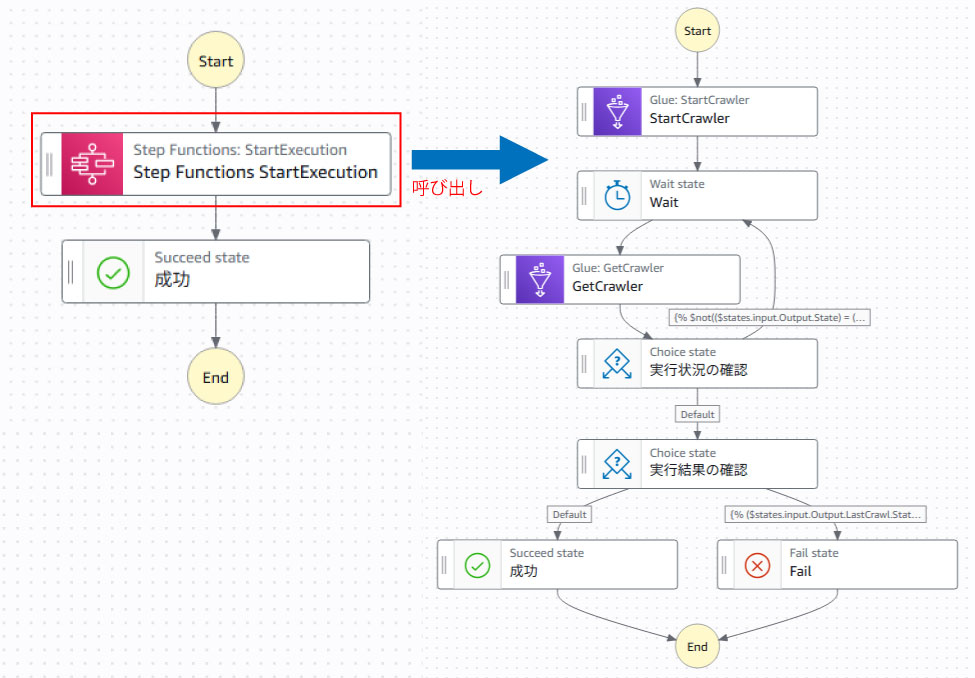
エラー時にCrawlerの実行からリドライブしたい場合
Crawlerの実行がエラーになった際に、StepFunctionsのリドライブで再実行できるようにしたい場合は、Crawlerの実行と実行結果の判定部分を子ステートマシンとする方法があります。
以下のように親のステートマシンから呼び出すようにすれば、Crawlerでエラーがあった場合に親ステートメントでリドライブすればCrawlerを再実行することができます。
他にも、LambdaでCrawlerの実行と実行結果の判定を実施するようにすることでリドライブの運用に対応することができます。
ただし、Lambdaの実行時間には最大15分の制限があるため、Crawlerの実行がこの制限に収まらない場合はこの方法は使えないため、注意が必要です。
まとめ
以上がStep FunctionsでCrawlerの実行結果を判定する方法です。
わざわざエラーハンドリングするためのフローを作らないといけないのは面倒ですが、ETL処理なんかでは使用する機会がそれなりにあると思うので、覚えておいて損はないと思います。
【PR】


コメント